内存大页的好处
现代CPU中就出现了TLB(Translation Lookaside Buffer) Cache用于缓存少量热点内存地址的mapping关系。然而由于制造成本和工艺的限制,响应时间需要控制在CPU Cycle级别的Cache容量只能存储几十个对象。那么TLB Cache在应对大量热点数据Virual Address转换的时候就显得捉襟见肘了。我们来算下按照标准的Linux页大小(page size) 4K,一个能缓存64元素的TLB Cache只能涵盖4Kx64 = 256K的热点数据的内存地址,显然离理想非常遥远的。
假设我们把Linux Page Size增加到16M,那么同样一个容纳64个元素的TLB Cache就能顾及64x16M = 1G的内存热点数据,这样的大小相较上文的256K就显得非常适合实际应用了。像这种将Page Size加大的技术就是Huge Page。
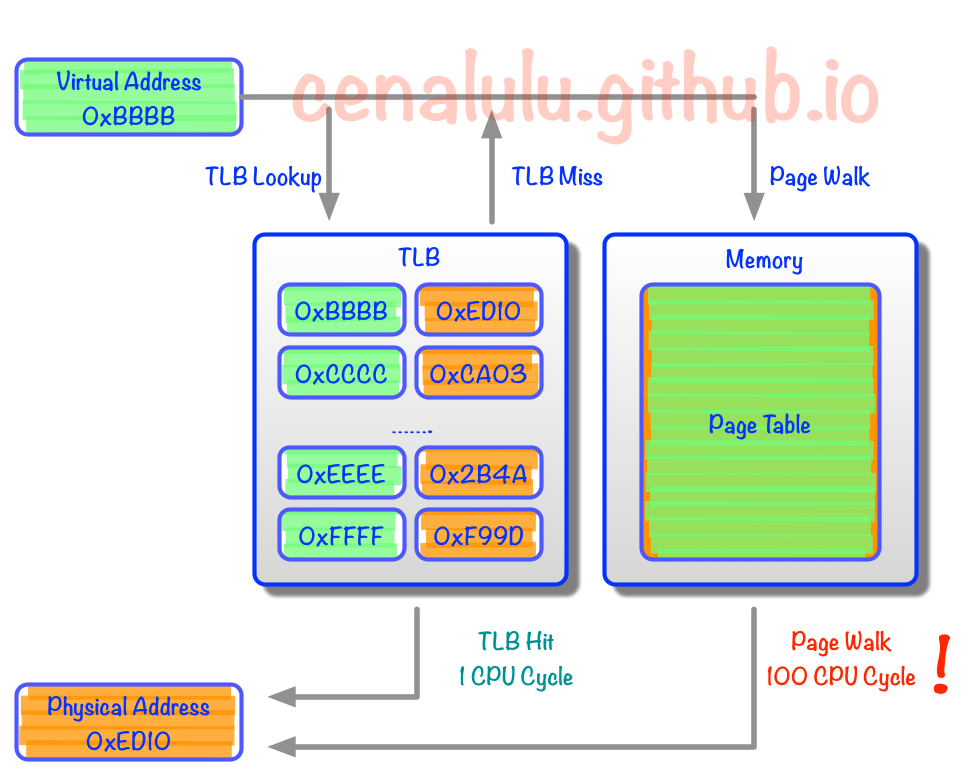
可以看出,如果一个页面被TLB缓存了,地址转换只需要1个CPU cycle, 而完整的页表查询,需要100个cycles。
开启THP(Transparent Huge Page)系统会产生一个khugepaged进程,他是THP的后台守护进程,主要功能是定时唤醒,根据配置尝试将4k 的普通page转成2M等巨页,减少TLB压力,提高内存使用效率。
内存大页在NUMA系统上的负面影响
现代主流服务器基本都是NUMA架构,大页通常带来的性能负面影响一般比收益要大,主要原因有两个:
-
CPU对同一个Page抢占增多 : 概率上统计,采用2M的页面,肯定会比4K的页面,更容易发生页面被跨NUMA的CPU并发访问。类比到数据库就相当于,原来一把用来保护10行数据的锁,现在用来锁1000行数据了。跨NUMA的内存并发访问会带来False Sharing问题,导致的延时通常比TLB missing要多几个数量级。
-
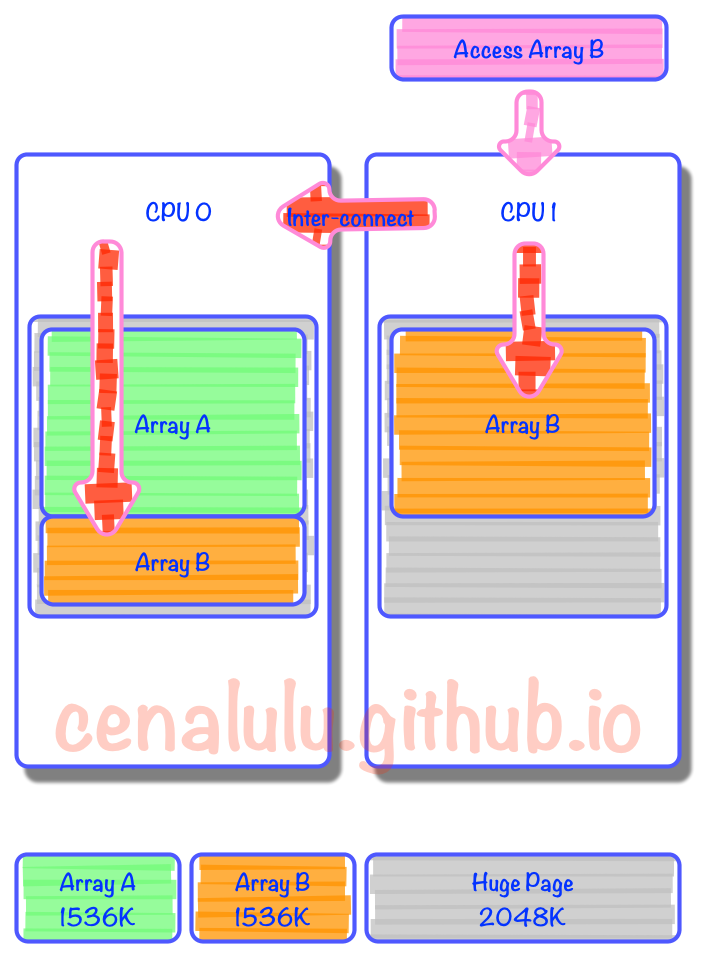
连续数据需要跨CPU读取 : 假设我们连续申明两个数组,Array A和Array B大小都是1536K。内存分配时由于第一个Page的2M没有用满,因此Array B就被拆成了两份,分割在了两个Page里。而由于内存的亲和配置,一个分配在Zone 0,而另一个在Zone 1。那么当某个线程需要访问Array B时就不得不通过代价较大的Inter-Connect去获取另外一部分数据。
Linux的内存大页配置
关闭THP:
kernel的启动参数可以通过传入:
transparent_hugepage=never
系统启动后:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
khugepaged 主要配置:
| 配置 | 说明 |
|---|---|
| 配置目录 | /sys/kernel/mm/transparent_hugepage/khugepaged |
| pages_to_scan | 配置khugepaged 后台进程一次处理的页面 |
| scan_sleep_millisecs | 配置khugepaged 后台进程唤醒的时间间隔 |