终点只是一个新的开始
在学习软件开发的时候,通常当程序被翻译到汇编指令的时候,我们就认为这就已经是最底层的终点了,剩下的就是等着CPU会去逐条执行这些指令。直到突然最近的某一天,一个Google Project Zero实验室22岁的小伙子搞出了一个expliot程序,居然能从CPU缓存中读出来一些根本就不该存在的敏感数据,我们才开始意识到原来CPU这个软件执行的终点,其实只是一个新的起点。
CPU流水线(Pileline)
先看下面的几条简单的汇编指令, 它们在现代Intel X86 CPU上是串行执行的么?答案其实就没那么简单!
mov edx, [eax]
mov eax, ebx
add ecx, eax
众所周知,现代计算机体系结构,存储有很多层次,各个层次硬件访问延迟存在数量级上的差异,越高的性能,往往意味着更高的成本和更小的容量。
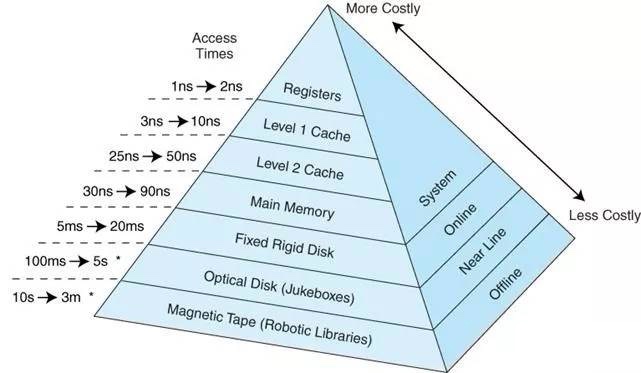
第一条指令因为要访问内存,相比随后的寄存器访问指令可能要慢上百倍,如果CPU采用严格的串型执行方式,可能一条高延时的指令会block后面的低延时指令很长时间,CPU上强大的ALU(算术逻辑单元)在这时候没有用武之地,只能等着数据被加载进来。Intel在X86 CPU持续投入了30多年,直到今天成为芯片领域的老大,肯定不是吃干饭的, 从20年前I486开始就开始引入了如下图的指令流水线(Pipeline)架构:
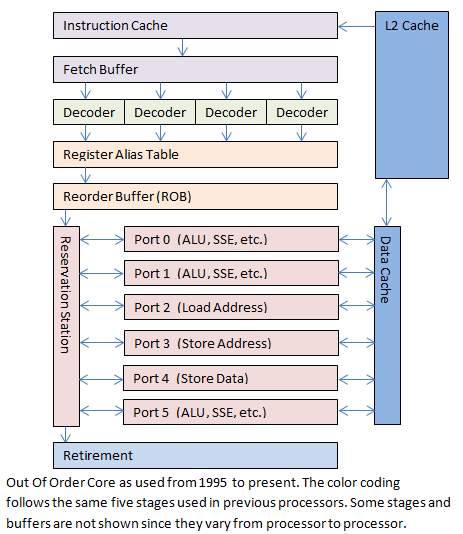
指令先会被加载到缓存,然后翻译成微指令,翻译完成后,它们会进入一个重排序缓存(Reorder Buffer, ROB), 不同的微指令在不同的执行单元中同时执行,而且每个执行单元都全速运行。只要当前微指令所需要的数据就绪,而且有空闲的执行单元,微指令就可以立即执行,有时甚至可以跳过前面还未就绪的微指令。通过这种方式,需要长时间运行的操作不会阻塞后面的操作,流水线阻塞带来的损失被极大的减小了。
现代CPU都设计有多路(Port)执行单元, 有些执行单元专门用来处理ALU, 比如加,减等; 有些用来处理SIMD, 比如矩阵乘加等;由于Pipeline多路执行的机制,CPU每个Cycle不止执行一条指令,比如上面的Pipeline例子中,一共有6个Ports, 所以该CPU的理论IPC(Instruction Per Cycle)至少大于等于6,如果熟悉perf命令,我们可能会注意到类似下面输出的“insn per cycle”会大于1。
[root@hubei ~]# perf stat sleep 1
Performance counter stats for 'sleep 1':
0.535761 task-clock (msec) # 0.001 CPUs utilized
1 context-switches # 0.002 M/sec
0 cpu-migrations # 0.000 K/sec
173 page-faults # 0.323 M/sec
981,520 cycles # 1.832 GHz (67.96%)
788,847 stalled-cycles-frontend # 80.37% frontend cycles idle
549,937 stalled-cycles-backend # 56.03% backend cycles idle
678,855 instructions # 0.69 insn per cycle
# 1.16 stalled cycles per insn
133,763 branches # 249.669 M/sec
7,942 branch-misses # 5.94% of all branches (47.82%)
1.006474001 seconds time elapsed
分支预测和推测执行
你会注意到上面提到过很重要的一个问题:如果执行指令的位置发生了跳转会发生什么?例如,当指令运行到”if”或者是”switch”时,会发生什么呢?在较老的处理器中这意味着清空流水线,等待新的跳转目的指令的取指执行。
当CPU指令队列中存储了超过100条指令时,发生流水线阻塞带来的性能损失是极其严重的。所有的指令都需要等待跳转目的的指令取回并且重启流水线。在这种情况下,需要将跳转指令之后但是已经执行的微指令全部取消掉,返回到执行前的状态。当所有乱序执行的微指令都退出乱序执行部件之后,将它们丢弃掉,然后从新的地址开始执行。这对于处理器来说是相当困难的,而且发生的频率很高,因此对性能的影响很大。这时,引入了乱序执行部件的另外一个重要功能。
答案就是猜测执行。猜测执行意味着当遇到一个分支指令后,会将所有分支的指令都执行一遍。一旦分支指令的跳转方向确定后,错误跳转方向的指令都将被丢弃。通过同时执行两个跳转方向的指令,避免了由于分支跳转导致的阻塞。处理器设计者还发明了分支预测缓存,当面临多个分支时进行预测,进一步提高了性能。虽然CPU阻塞仍然会发生,但是这个解决方案将CPU发生阻塞的概率降到了一个可以接受的范围。
著名的GCC编译器提供了两个宏定义,分别是likely和unlikely,我们在看Linux Kernel源代码的时候会经常看到它们,其实likely就是告诉编译器这个分支下面包括的代码发生的概率很大,所以请帮助我把它们放到尽量靠近这个分支语句的地方,这样CPU的猜测执行就可以更省事一点,有更多的概率不用去加载执行另外分支的指令。
这个机制在过去的20多年一直都运行的很好,直到文章前面提到的Google那个22岁的小伙,从Intel的手册中注意到推测执行并没有做任何权限控制,写了几行非常有想象力的代码,然后就是Intel就快被搞疯了。。。