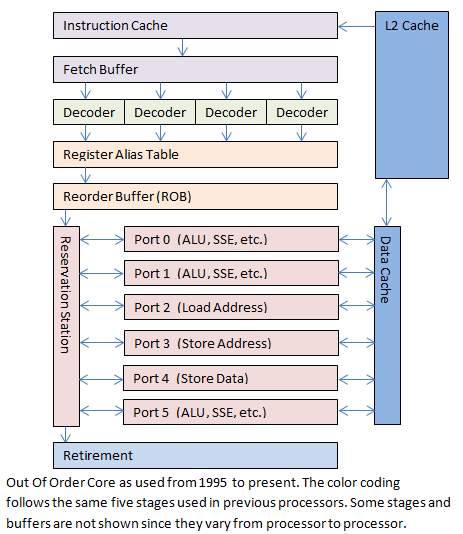
现代CPU是以流水线的方式加载并执行代码,当指令运行到
if或者是switch时,这意味着清空流水线,等待新的跳转目的指令的取指执行。在这种情况下,需要将跳转指令之后但是已经执行的微指令全部取消掉,返回到执行前的状态。当所有乱序执行的微指令都退出乱序执行部件之后,将它们丢弃掉,然后从新的地址开始执行。因此,高频率的分支判断对性能的影响很大。
Bad Branch Prediction
下面这段程序完成对一段随机数数组的累加:
#include <stdlib.h>
#include <stdio.h>
int main()
{
const unsigned arraySize = 32768;
int data[arraySize];
srand(1);
for (unsigned c = 0; c < arraySize; ++c)
data[c] = rand() % 256;
long long sum = 0;
for (unsigned i = 0; i < 100000; ++i)
{
for (unsigned c = 0; c < arraySize; ++c)
{
if (data[c] >= 128)
sum += data[c];
}
}
printf("sum=%lld\n", sum);
return 0;
}
但是在我的执行环境上,它耗时20s:
[root@hluo bad-prediction]# time ./a.out
sum=314931600000
real 0m20.089s
user 0m20.086s
sys 0m0.003s
用perf统计程序主要的消耗,可以看出branch-misses达到11。57%:
[root@hluo bad-prediction]# perf stat ./a.out
sum=314931600000
Performance counter stats for './a.out':
20054.708176 task-clock (msec) # 1.000 CPUs utilized
31 context-switches # 0.002 K/sec
1 cpu-migrations # 0.000 K/sec
78 page-faults # 0.004 K/sec
68,807,947,748 cycles # 3.431 GHz
46,009,391,440 instructions # 0.67 insn per cycle
13,123,331,576 branches # 654.377 M/sec
1,518,895,782 branch-misses # 11.57% of all branches
20.055717912 seconds time elapsed
减少循环中的分支
很显然,避免循环中的分支会大幅提升程序的性能,因此我们把主循环改成这个样子:
for (unsigned c = 0; c < arraySize; ++c)
{
int t = (data[c] - 128) >> 31;
sum += ~t & data[c];
}
用time看下执行时间,提升了一倍多。
[root@hluo bad-prediction]# time ./a.out
sum=314931600000
real 0m7.354s
user 0m7.352s
sys 0m0.002s
再用perf看下关键事件,branch-miss没有了。
[root@hluo bad-prediction]# perf stat ./a.out
sum=314931600000
Performance counter stats for './a.out':
7639.060318 task-clock (msec) # 1.000 CPUs utilized
17 context-switches # 0.002 K/sec
1 cpu-migrations # 0.000 K/sec
81 page-faults # 0.011 K/sec
25,198,771,742 cycles # 3.299 GHz
68,849,384,484 instructions # 2.73 insn per cycle
6,560,526,320 branches # 858.813 M/sec
295,065 branch-misses # 0.00% of all branches
7.640186227 seconds time elapsed