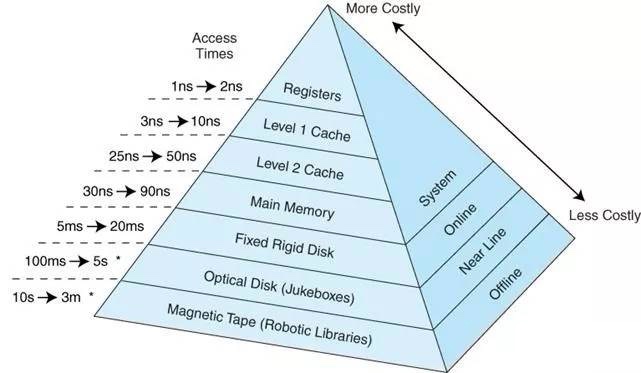
现代计算机体系结构,存储有很多层次,各个层次硬件访问延迟存在数量级上的差异,越高的性能,往往意味着更高的成本和更小的容量。因为不同层级之间的性能差距一般是指数级别, 如何有效利用高性能的存储介质,对应用程序的性能影响很大。
下面两段程序的时间复杂度完全一致, 都是对一个数组执行n次置1操作,但是在我的执行环境上,前者耗时1.17s, 而后者耗时仅为0.14s。
这是因为前者循环中,使用随机方式对数组访问,会造成大量的cache miss, 而后者顺序访问,cache miss几乎可以忽略不计
用perf stat -e cache-misses ./a.out可以看出,前者cache-miss数量35,430,879, 而后者仅有372,681。
随机访问大量cache miss的测试代码:
#include <stdlib.h>
#define MISS 39321600
int main(){
int *p = (int*)malloc(MISS * sizeof(int));
int i;
for(i=0; i<MISS; i++) {
p[random() % MISS] = 1;
}
}
顺序访问优化cache miss后的测试代码:
#include <stdlib.h>
#define MISS 39321600
int main(){
int *p = (int*)malloc(MISS * sizeof(int));
int i;
for(i=0; i<MISS; i++) {
p[i] = 1;
}
}